はじめに
はじめまして、Hololensチームの信久です。
xRにはコンピュータービジョンは不可欠です。それはMRでは現実世界を理解するにはコンピュータービジョンが必要であって、VRにもヘッドトラッキングやコントローラートラッキングのためにカメラ使われることが多く、こういう場合にもコンピュータービジョンが使われているからです。
そのためxRをもっと深く理解するにはその根本の一つとなるコンピュータービジョンを理解する必要があるので、今回はxRに使われるコンピュータービジョンの基本的な知識を紹介します。
画像処理とコンピュータービジョンの違い

よく誤解されるのは、画像処理とコンピュータービジョンの違いです。両方もカメラのピクセル情報を利用して入力画像とは異なる何かを出力するが、画像処理は名前通りに、ただその画像の「処理」を行うのですが、それ以上はしません。
例えば、写真の明るさの調整、カラー画像からモノクロにする処理などは「画像処理」となります。
では、コンピュータービジョンとはなんですか?
コンピュータービジョンは画像を「理解」しようとします。人間と同じく画像に写っている物のいかなる情報の理解しようとするのはコンピュータービジョンの領域です。
例えば、顔検出、バックグラウンド検出、写真から3D化するとかは「コンピュータービジョン」となります。
実際に、コンピュータービジョンにも画像処理がよく使われていて、コンピュータービジョンを理解するにはある程度画像処理の理解も必要です。
現実世界の理解の基本:【特徴点】(Feature Points)

コンピュータビジョンの世界では、コンピューターはカメラを利用して現実世界を理解しようとするのですが、結局の所、カメラから得られるデータは2D配列のカラー値(RGB)、もしくは赤外線カメラみたいに光度の値だけです。二次元配列に存在するそれらの値は「ピクセル」と呼ばれますが、このピクセルデータからどうやって世界の「理解」が出来るのでしょうか?。
いろんなアプローチがあるのですが、今回紹介するのは画像の【特徴点】(Feature Points) というものです。
特徴点はパノラマ構成から世界の3D再構成まで幅広く使われますが、特徴点って一体何でしょうか?
画像の【特徴】(Features)
一つの写真から得られるシーン(場所)の情報は少ないが、同じシーンの別角度写真、もしくはシーンの動画から、その空間の理解が広がって情報が得られやすくなります。
だから、まずは同じシーンの複数写真を『同じシーン』だと特定出来る何かを探さなければ行けないのですが、これらのことを【特徴】 (Features) と言います。
使えそうな「いい特徴」は次のルールを守らなければ行けない:
- 他の写真にも見えること
- 明確的に特定出来ること
- 確実的に特定出来ること
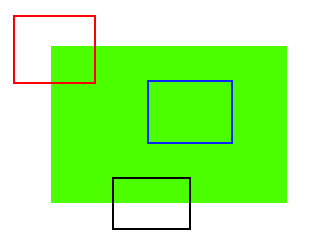
画像処理を利用して、画像からエッジ線だけの画像にして、それらの線を特徴にも使えますが、上の条件に当てはまるのは、2つ以上のエッジから生み出される「コーナー」 (Corner) となります。
コーナー検出法 (Corner Detection)

幾何学的な話になりますが、コーナー (Corner) というのは2つのエッジ (Edge) の交点です。そして、コーナーの周りにははっきりとした方向を持つ2つ以上のエッジが存在する。
このコーナーを検出するには、複雑なアルゴリズムが使われますが、簡単にそのアルゴリズムの説明すると、数ピクセルの小さな検出窓を作って、上から下、そして左から右に移動して検出を行う。
コーナーに入った瞬間、その窓をどの方向に移動しても、大きな値の変化が見られるので、コーナーだと仮定する。値の変化はコーナーによって特徴的なので、その情報とコーナーの位置を揃えばちゃんと「特徴点」として使えます。
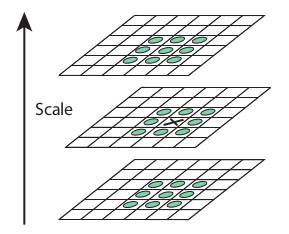
でもただのコーナーは適切な特徴点とは言えない、なぜなら、コーナー検出法で特定出来るコーナーはスケールに弱いからです。複数画像の場合、検出出来るコーナーは同じサイズでなければ、同じ特徴点として認識されず、上に書かれてある条件の「明確的に特定出来ること」に違反します。
ただし、コーナー検出+アルファを利用するアルゴリズム使えば、適切な特徴点が得られます。
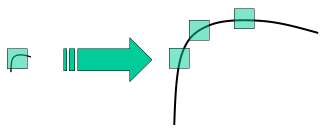
SIFT
一番有名で幅広く使われている特徴点検出アルゴリズムは「SIFT」と言って、「Scale Invariant Feature Transform」の略になりますが、日本語にすると「スケール不変の特徴変換」という名前になります。名前の通り重要な点はスケール関係なく特徴点が検出できるという点です。
このアルゴリズムを簡単に説明するとコーナーがある所に複数スケールの検出窓でのコーナー検出を行って、特徴点情報にスケール情報を追加します。
特徴点の利用の例:パノラマ構成

例として、パノラマを作るには大体複数の画像を合成しなければ行けないのですが、昔から自分の目を利用して手動でパノラマを作る方法がありますが、人間と同じく、もしくはそれに上回る正確さでコンピューターはパノラマ合成が出来るのでしょうか?
上に習った特徴点を使えば簡単に出来ます。やり方は次の通りです。
- パノラマを作るための複数写真を用意する
- すべての写真からSIFTか他の特徴点検証アルゴリズムを利用して特徴点を探します
- とある写真をスタートポイントにして、他の写真と特徴点のマッチングを行う(同じ特徴点を持っているかどうかを確認する作業です)
- マッチングがあった場合、写真の特徴点がマッチングした前の写真と同じ場所にあるようにトランスフォームをかける(スケール・回転・移動を行う)
- 次の写真からマッチングを行って、全ての写真からマッチング行った時点で終わり
最後に
今回はコンピュータビジョンとはなにか、特徴点とは何か、特徴点の検証方法と特徴点の利用例を紹介しました。
次は、もうちょっとxRと関係する特徴点の使い方を紹介するので、次のブログでまた会いましょう。





{kind=link}